Abstract
Designing proper experiments and selecting optimal intervention targets is a longstanding problem in scientific or causal discovery. Identifying the underlying causal structure from observational data alone is inherently difficult. Obtaining interventional data, on the other hand, is crucial to causal discovery, yet it is usually expensive and time-consuming to gather sufficient interventional data to facilitate causal discovery. Previous approaches commonly utilize uncertainty or gradient signals to determine the intervention targets. However, numerical-based approaches may yield suboptimal results due to the inaccurate estimation of the guiding signals at the beginning when with limited interventional data. In this work, we investigate a different approach, whether we can leverage Large Language Models (LLMs) to assist with the intervention targeting in causal discovery by making use of the rich world knowledge about the experimental design in LLMs. Specifically, we present Large Language Model Guided Intervention Targeting (LeGIT) -- a robust framework that effectively incorporates LLMs to augment existing numerical approaches for the intervention targeting in causal discovery. Across 4 realistic benchmark scales, LeGIT demonstrates significant improvements and robustness over existing methods and even surpasses humans, which demonstrates the usefulness of LLMs in assisting with experimental design for scientific discovery.
LeGIT Framework
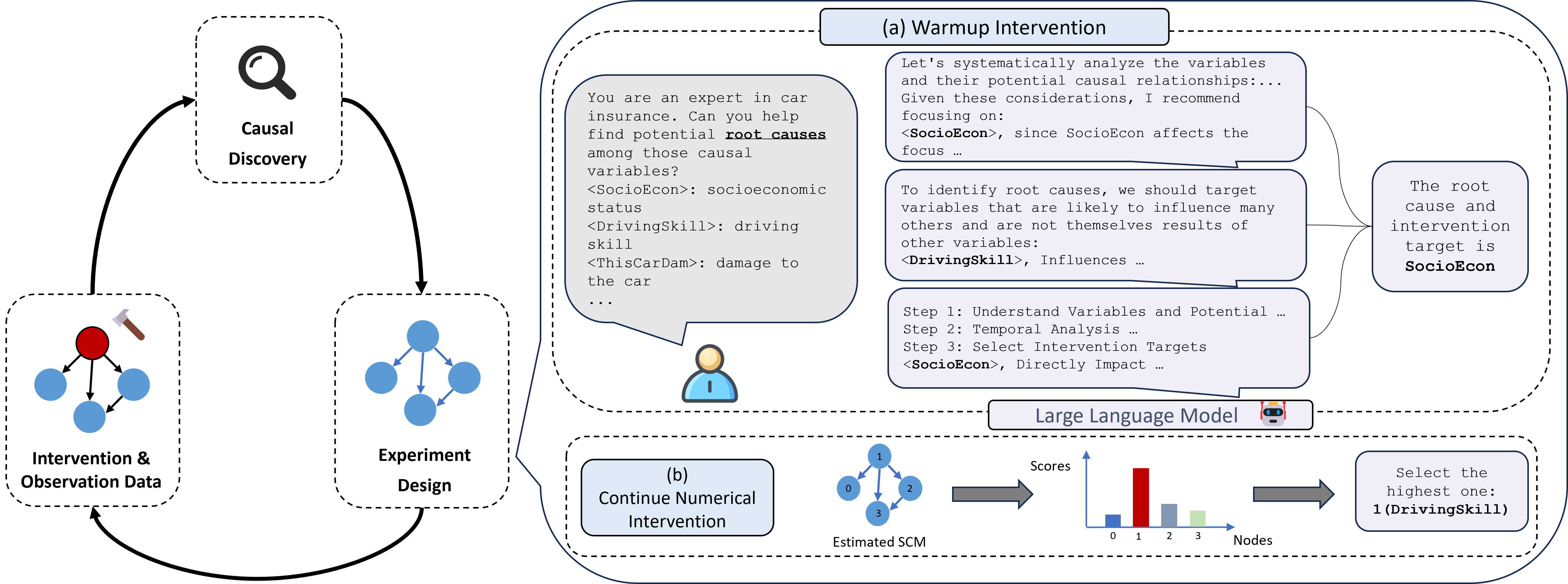
Figure 1. Illustration of the LeGI framework.
Challenges in Existing Intervention Targeting
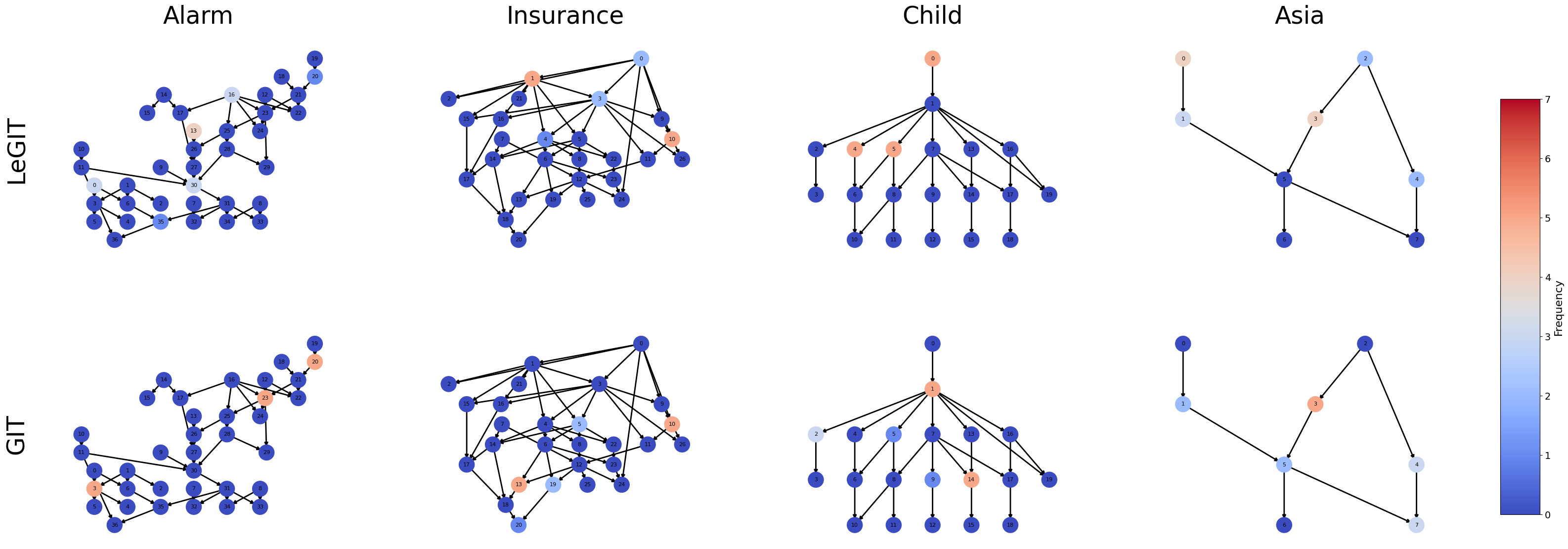
Figure 2. At the initial stage of the online causal discovery, the intervention targets from LLM-based selection and gradient-based selection.

Box 1. Prompt template at warmup stage.
Results on Realistic Benchmarks
We evaluate LeGIT on four realistic causal discovery benchmarks: Asia, Child, Insurance, and Alarm. We compare LeGIT against different online causal discovery algorithms GIT, AIT, CBED as selection strategies for online active learning interventions, as well as three random baselines and human baseline.
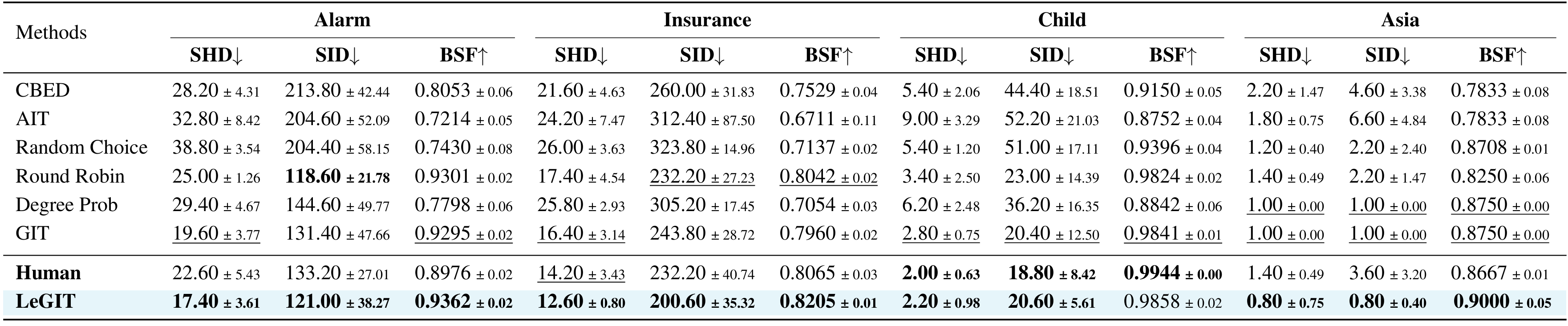
Table 1. Average SHD, SID, and BSF with standard deviation (over 5 seeds) for real-world data (T = 33 rounds,|Dint| = 32,N = 1056).
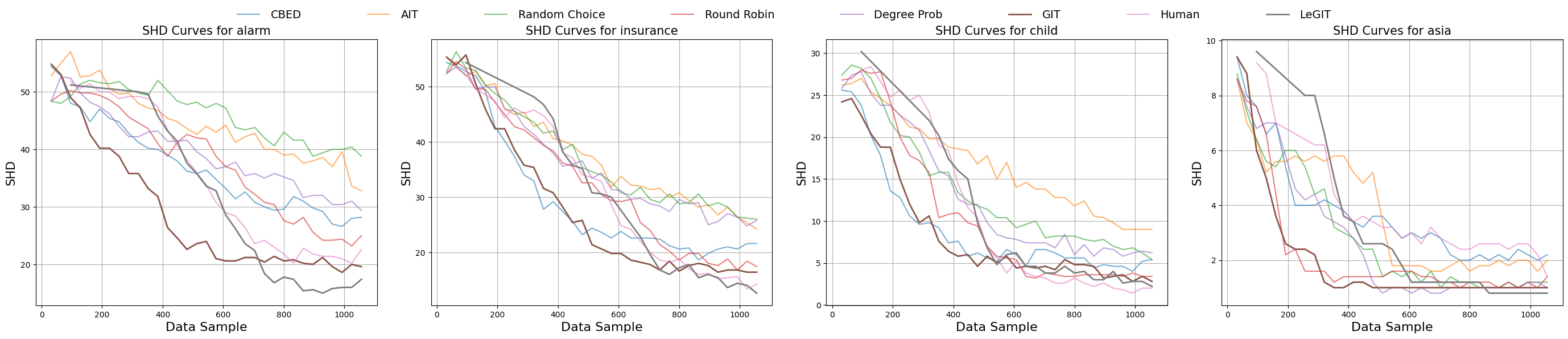
Figure 3. SHD metric for different methods (over 5 seeds) towards different intervention samples (T = 33 rounds,|Dint| = 32,N = 1056).
Main Result: LeGIT achieves state-of-the-art causal discovery performances, with consistent improvements against the adopted gradient-based methods and human baseline. The superior SHD (Structural Hamming Distance) scores indicate that LeGIT reconstructs causal graphs more accurately, requiring fewer erroneous edge modifications. The SID (Structural Intervention Distance) results highlight LeGIT's robustness in preserving causal relationships, ensuring reliable causal inferences, which is crucial for real-world applications. Additionally, the BSF metric demonstrates that LeGIT produces graphs that more accurately reflect true causal structures. As shown in Figure 3, while LeGIT initially does not perform optimally in online causal discovery, it quickly converges to a superior solution as more intervention data becomes available. In contrast, GIT, despite a faster initial improvement, ultimately converges to a suboptimal solution due to poor initialization.
Table 2. Average SHD, SID, and BSF with standard deviation (over 5 seeds) for real-world data with a low data budget (T = 33 rounds,|Dint| = 16,N = 528).
LowDataExperiment Analysis: This low-data setting is more practically relevant. Additionally, due to the insufficient intervention data, the performance of causal discovery algorithms in estimating effects is diminished, which further tests the effectiveness of the intervention strategy. Table 2, show that LeGIT achieves larger improvements under these conditions in 3 complex datasets. These findings highlight the effectiveness of LeGIT in real-world experimental design scenarios, where both the number of interventions and the sample size are limited. The result of the low-data experiment further verifies our discussion that numerical methods suffer from noise or insufficient data, leading to a suboptimal solution. the use of LLMs enables scalable and effective guidance that complements numerical methods, reducing the risk of suboptimal convergence, and having more stable performance in real-world applications.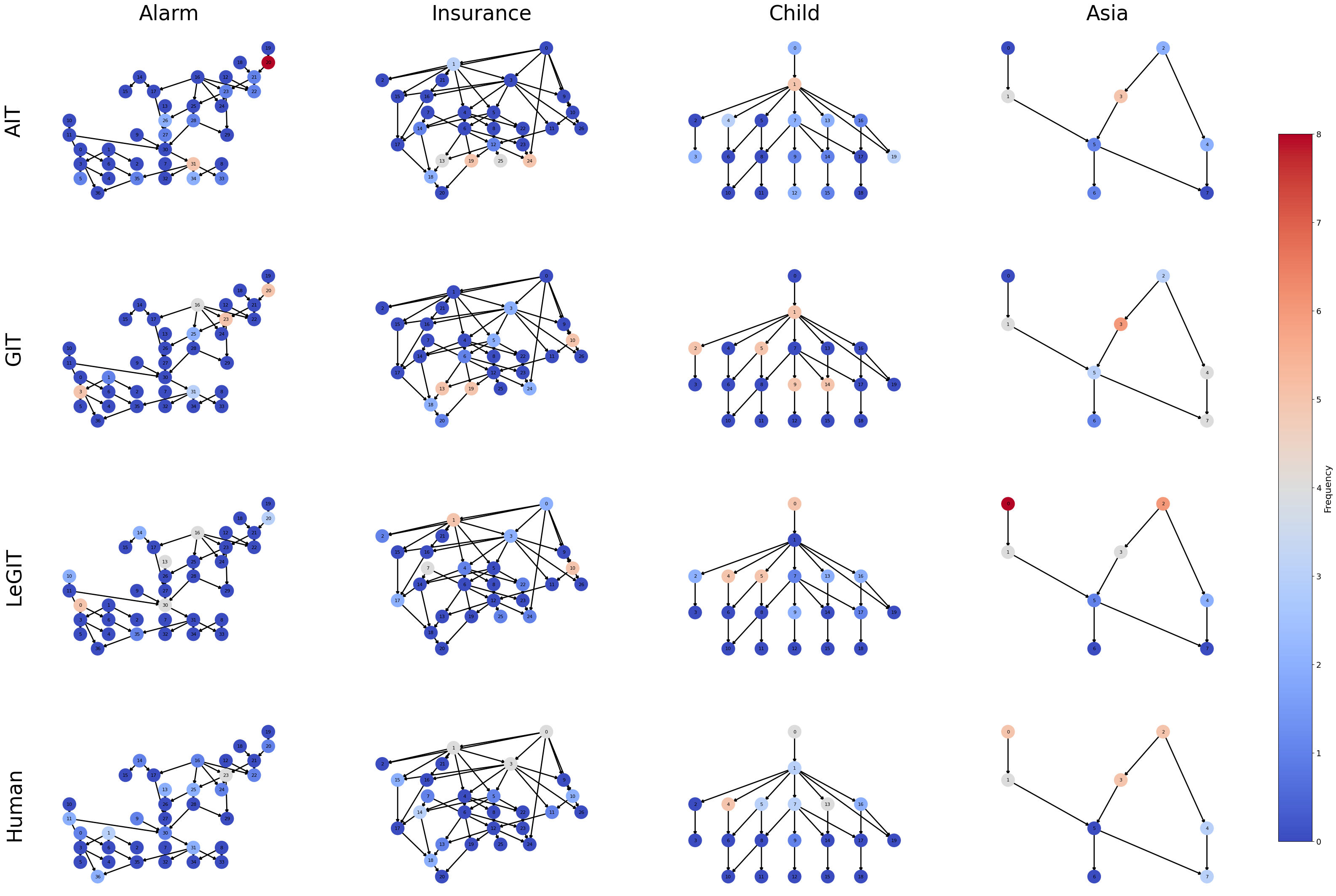
Figure 4. The selected Node Frequency obtained by different strategies on Epoch 0-4 from 5 different seeds under Table1 setting.
Detailed comparisons and analyses: Figures 4 illustrate the distribution of selected nodes over the first five epochs. Numerical methods like GIT and AIT struggle during initialization, frequently selecting peripheral or leaf nodes in datasets like Insurance and Alarm, leading to suboptimal interventions. In contrast, LeGIT effectively identifies central and influential nodes, such as SocioEcon in the Insurance dataset, which plays a key role in determining car choice, driving behavior, and safety affordability. Compared to the Human baseline, LeGIT outperforms in complex datasets (Alarm and Insurance), particularly when dealing with a large number of variables, where finding optimal interventions becomes computationally challenging. Human experts may exhibit subjective biases or oversimplified mental models, making the process tedious and error-prone. Additionally, LLMs (as referenced in Figures 1) provide a systematic and scalable approach by following structured prompts and leveraging background knowledge. With the self-consistency prompt technique, LLMs generate more robust and reliable results, serving as a cost-effective alternative to multiple human experts. The primary advantage of LLMs lies in scalability and real-time availability, particularly for online causal discovery, where rapid interventions are required. They excel in large-scale systems where human experts cannot manually assess all variables. By complementing human oversight, LLMs help reduce biases, improve consistency, and accelerate metadata processing, ultimately saving experts time and providing a solid foundation for causal discovery.Conclusion
In this work, we investigated how to incorporate LLMs into the intervention targeting in experimental design for causal discovery. We introduced a novel framework called LeGIT, which combines the best of previous numerical-based approaches and the rich knowledge in LLMs. Specifically, LeGIT leverages LLMs to warm up the online causal discovery procedure by identifying the influential root cause variables to begin the intervention. After setting up a relatively clear picture of the underlying causal graph, LeGIT then integrates the numerical-based methods to continue to select the intervention targets. Empirically, we verified the effectiveness of LeGIT leveraging LLMs to warm up the online causal discovery can achieve the state-of-the-art performance across multiple realistic causal discovery benchmarks. Furthermore, we compared its performance against a human baseline, highlighting its unique value. LLMs offer a scalable and cost-effective approach to enhance experimental design, paving the way for new research directions of causal analysis and scientific discovery fields.
Contact
Welcome to check our paper for more details of the research work. For any question, please feel free to contact us.
If you find our paper and repo useful, please consider to cite:
@inproceedings{Li2025CanLL,
title={Can Large Language Models Help Experimental Design for Causal Discovery?},
author={Junyi Li and Yongqiang Chen and Chenxi Liu and Qianyi Cai and Tongliang Liu and Bo Han and Kun Zhang and Hui Xiong},
year={2025},
url={https://arxiv.org/abs/2503.01139}
}