"How can LLMs reliably assist in revealing the causal mechanisms behind the real world?"
COAT Framework
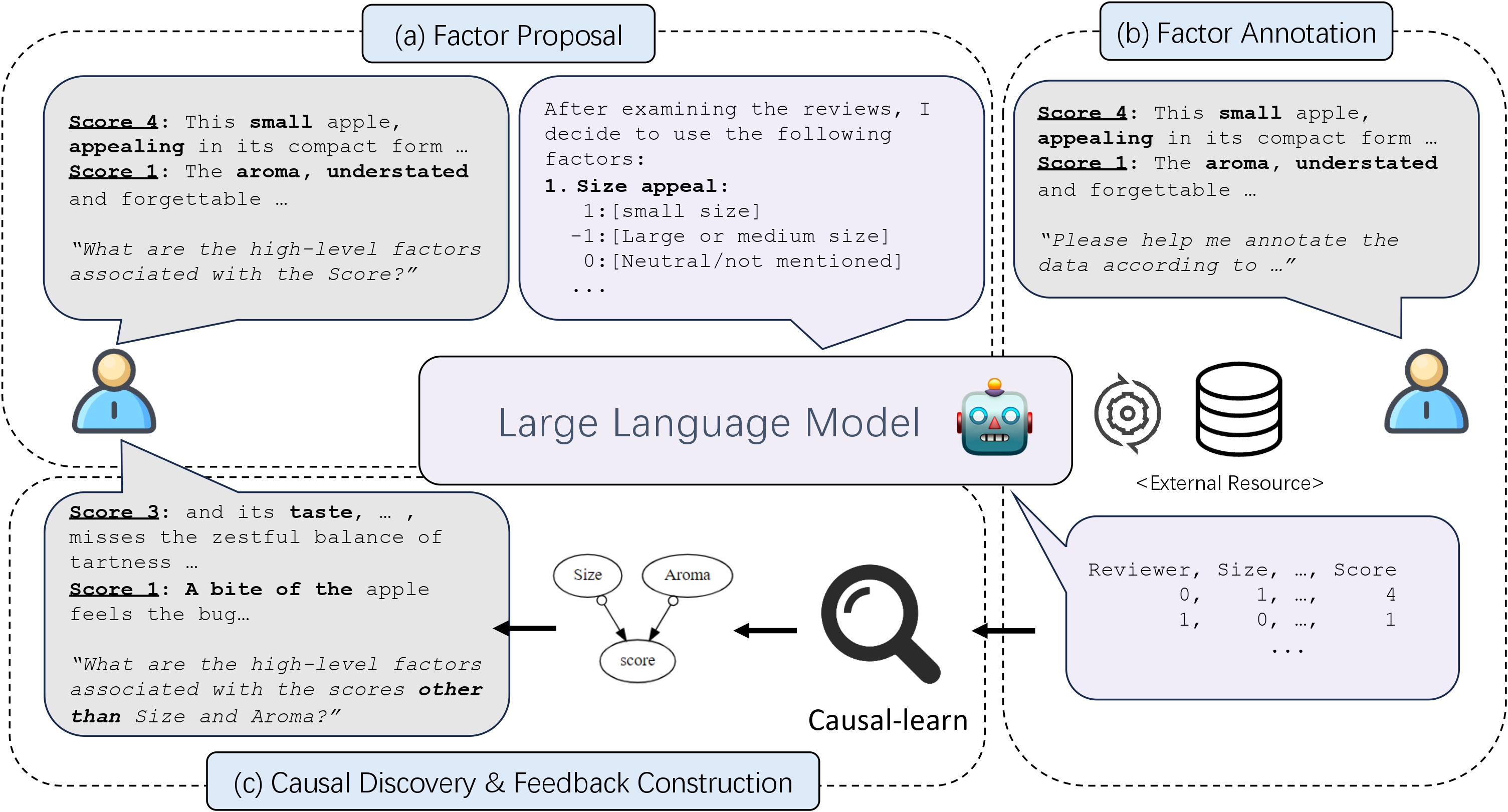
Figure 1. Illustration of the COAT framework.
Inspired by real-world causal discovery applications, given a new task with unstructured observational data, COAT aims to uncover the markov blanket with respect to a target variable:
- (a) Factor Proposal. COAT first adopts an LLM to read, comprehend, and relate the rich knowledge during pre-training to propose a series of candidate factors along with some meta-information such as annotation guidelines.
- (b) Factor Annotation. Based on the candidate factors, COAT then prompts another LLM to annotate or fetch the structured values of the unstructured data.
- (c1) Causal Discovery. With the annotated structured data, the causal discovery algorithm is called to find causal relations among the factors.
- (c2) Feedback Construction. By looking at samples where the target variable can not be well explained with the existing factors, LLM is expected to associate more related knowledge to uncover the desired causal factor.
Results on AppleGastronome Benchmark
In AppleGastronome benchmark, we consider the target variable as a rating score of the apple by astronomers. We prepare different high-level factors: 3 parents of Y, one child of Y, and one spouse of Y. These factors form a Markov blanket of Y. In addition, we also prepared one disturbing factor related to Y but not a part of this blanket. A good method is expected to propose the five high-level factors (up to semantical meanings) and exclude the disturbing factor.

Box 1. Examples of AppleGastronome data, grouped by the value of scores.
Main Result Empirically, LLMs with CoT can be aware of high-level factors behind data (lower OT than META) but still struggle to distinguish the desired factors in Markov Blanket (higher NMB than COAT ). COAT is more resistant to the ”disturbing” factor, which is supported by the lower NMB column. COAT filters out irrelevant factors from LLMs' prior knowledge that are not reflected by the data, which is supported by the lower OT column. COAT robustly encourages LLM to find more expected factors through the feedback, which is supported by the higher MB column.
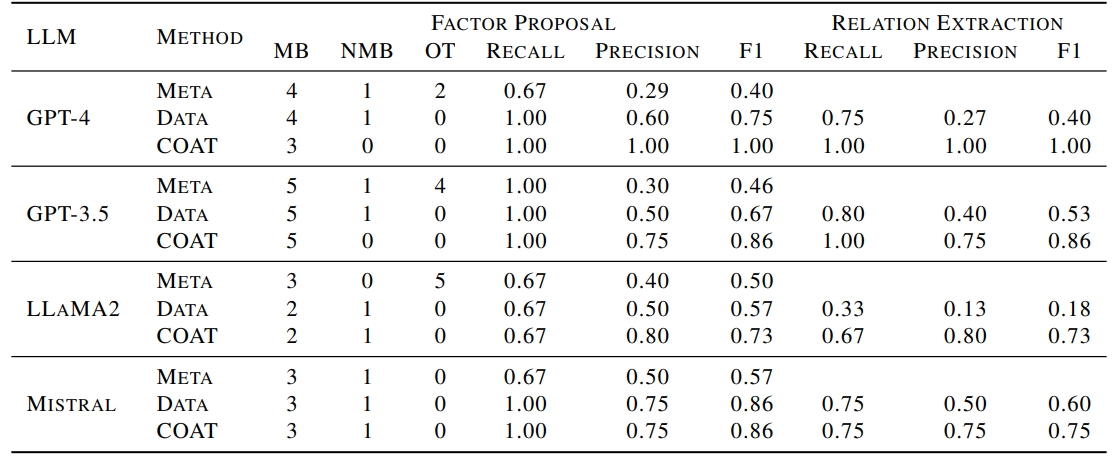
Table 1. Causal discovery results in AppleGastronome. MB, NMB and OT refer to the number of causal factors discovered in the underlying markov blanket, in the causal graph but not the markov blanket, and the other variables. Recall, precision, and F1 for factor proposal evaluate the discovered causal ancestors. Recall, precision, and F1 for relation extraction evaluate the recovery of the causal edges. The Data baseline refers to pairwise causal relation inference (Kiciman et al., 2023) based on the factors discovered by Data.
Can LLMs be an effective factor proposer? As discussed in Sec. 2.4 of paper, there are two crucial abilities for LLMs in identifying potential high-level factors. The first one is to be aware of the existence of potential factors, and the second is to synthesize and describe these factors. Inspired by this observation, we propose two novel metrics to quantify LLMs' causal ability: a) Perception that quantifies the ratio of valid factors (satisfying Prop. 2.1) proposed by LLMs in each round; b) Capacity that measures the effective mutual information drop in Assumption 2.2. As shown in Fig. 2(c), LLMs differ largely on the perception score while comparably on the capacity score.
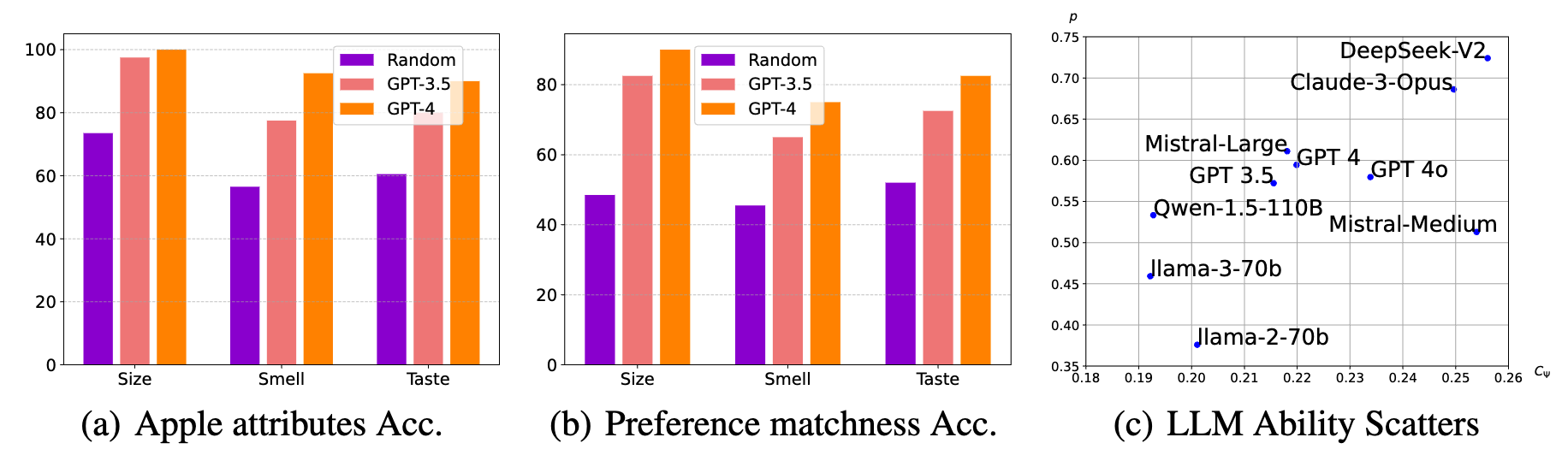
Figure 2. Quantitative evaluation of the causal capabilities of LLMs in COAT.
Can LLMs be an effective factor annotator? Moreover, since LLMs are also used to annotate the data according to the proposed annotation guidelines, we analyze the capabilities of LLMs in terms of annotation accuracy. As shown in Fig. 2(a-b), both GPT-3.5 and GPT-4 annotate subjective attributes well. Regarding objective human preferences, the performances are still relatively high. In addition, since the annotated results by LLMs will involve additional noises, or even additional confounders, we also conduct independence tests among the annotation noises and the features. It can be found that, with highly capable LLMs, e.g., GPT-4-Turbo, the dependencies can be controlled under an acceptable level.
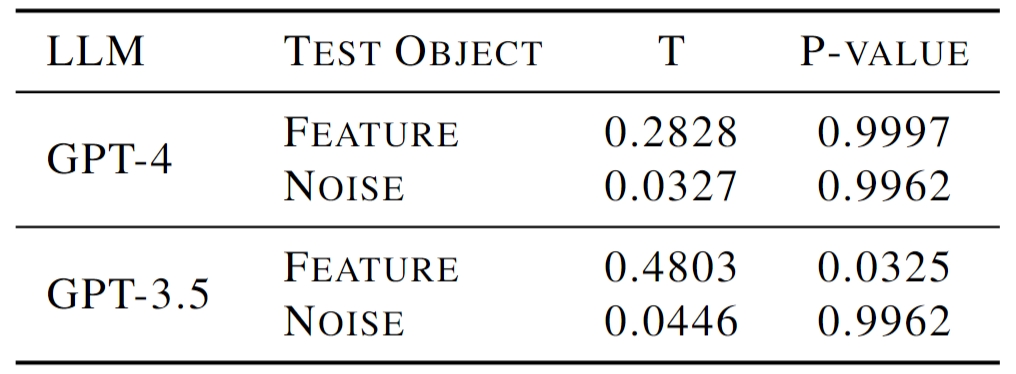
Table 2. Independence tests of the annotation noises with annotated features and other noises in AppleGastronome.
Can COAT reliably recover the causal relationships? We present qualitative results in Fig. 3. Compared to directly adopting LLMs to reason the causal relations, COAT significantly boosts the causal relation recovery. Meanwhile, COAT maintains high performances based on various LLMs, which further demonstrates the effectiveness of the causal feedback in COAT to improve the robustness of this system. In fact, the causal feedback focuses on making maximal use of the rich knowledge of LLMs, and reducing the reliance on the reasoning capabilities of different LLMs, to assist with causal discovery. We provide the full results of 10 LLMs in Appendix E.3.
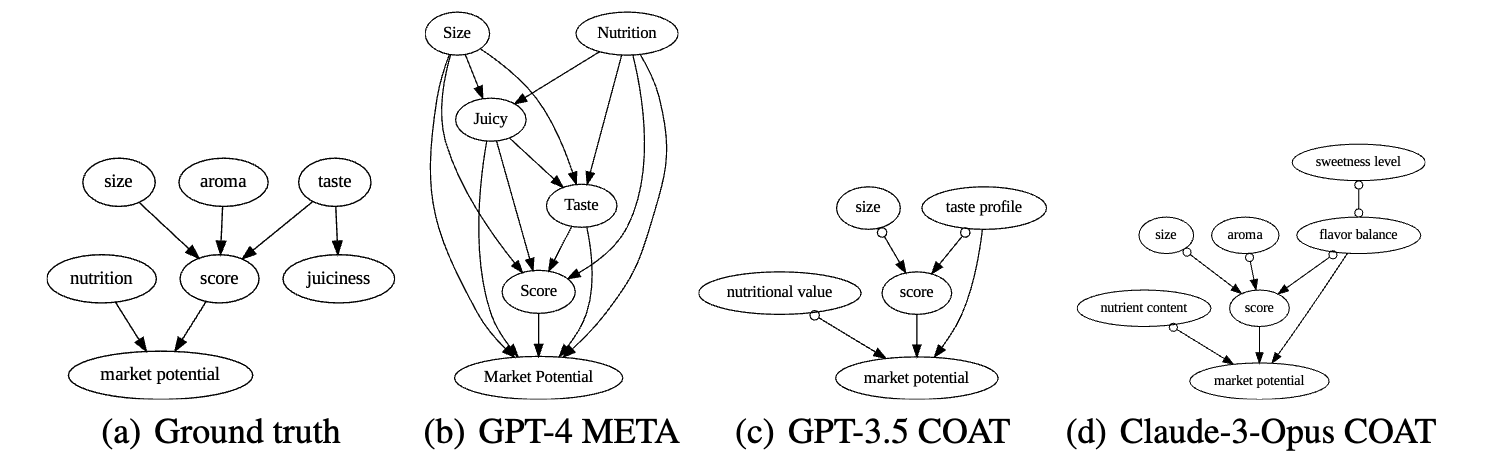
Figure 3. The discovered causal graphs in AppleGastronome.
Results on Neuropathic Benchmark
In the original dataset, there are three levels of causal variables, including the symptom-level, radiculopathy-level and the pathophysiology-level. In this project, we mainly consider the target variable of right shoulder impingement . When generating the clinical diagnosis notes as x using GPT-4, we will avoid any mentioning of variables other than symptoms .

Box 2. Examples of Neuropathic data, grouped by the presence of one certain symptom.
Factor proposal. Similarly, we can find that COAT consistently outperforms all of the baselines regardless of which LLMs are incorporated. In particular, COAT can boost the weakest backbone LLaMA2-7b to be better than any other LLMs.
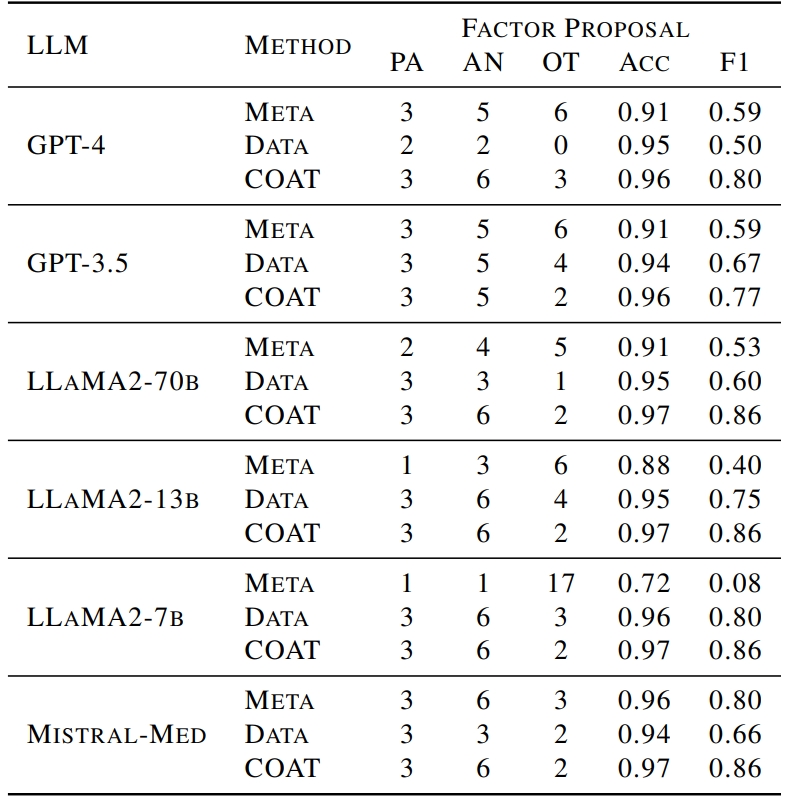
Table 3 . Causal discovery results in Neuropathic. PA, AN, and OT refer to the parents, ancestors, and others, respectively. Accuracy and F1 measure the recovery of the causal ancestors.
Causal relation recovery. Due to the faithfulness issue of the original dataset (Tu et al., 2019), we mainly conduct a qualitative comparison between the ground truth that is faithful to the data, against the baselines and COAT.

Figure 4. The discovered causal graphs in Neuropathic.
ENSO Case Study
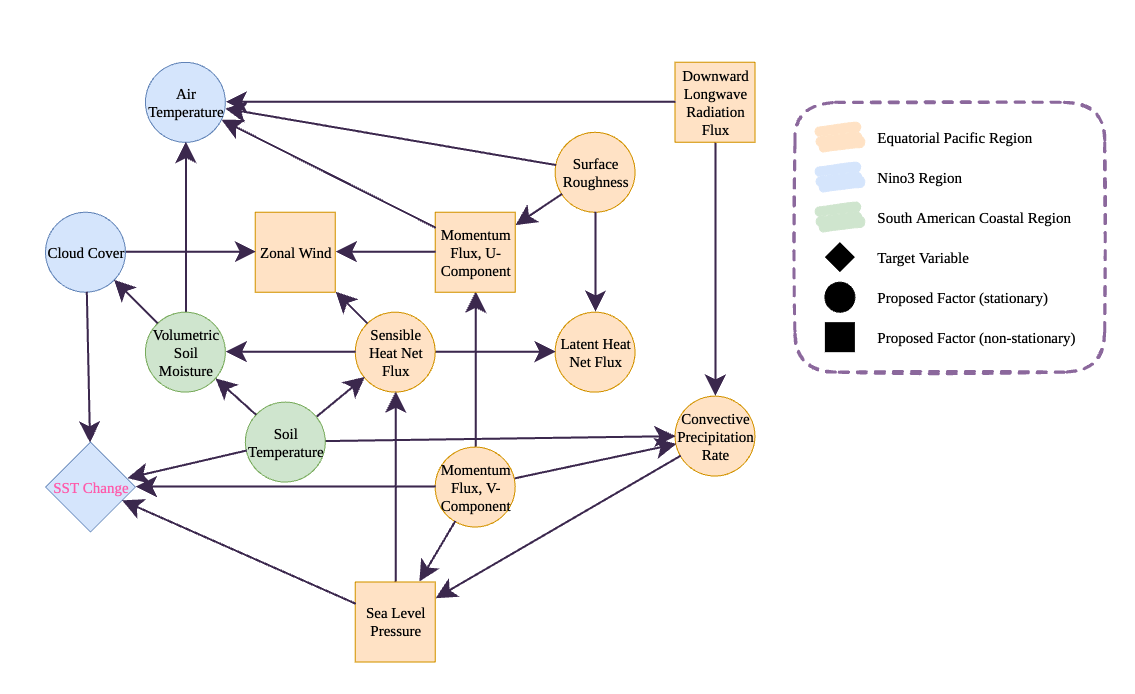
Figure 5. The final causal graph found by COAT in the ENSO case study
El Niño–Southern Oscillation (ENSO) Case study. El Niño-Southern Oscillation (ENSO) is a climatic phenomenon in the Pacific Ocean that influences global weather patterns profoundly. To understand its mechanism, we apply COAT on NOAA dataset. There are 13 factors identified by COAT , and their instantaneous causal relations are visualized in Fig 7. The target variable is the future change in monthly SST in the Nino3 region, which could be an important indicator of ENSO events. Each factor is a time series about a certain climate measurement above a specific level averaged over a specific region. The paths about Sea level Pressure, Momentum Flux, and Cloud Cover matches the existing understanding from literature. It also suggests several inserting hypotheses that are less explored in literature, like the path from Soil Temperature in South American Coastal Region. We refer details in the paper's Appendix K.
Contact
Welcome to check our paper for more details of the research work. For any question, please feel free to contact us.
If you find our paper and repo useful, please consider to cite:
@inproceedings{causalcoat2024,
author = {Liu, Chenxi and Chen, Yongqiang and Liu, Tongliang and Gong, Mingming and Cheng, James and Han, Bo and Zhang, Kun},
booktitle = {Advances in Neural Information Processing Systems},
editor = {A. Globerson and L. Mackey and D. Belgrave and A. Fan and U. Paquet and J. Tomczak and C. Zhang},
pages = {102307--102365},
publisher = {Curran Associates, Inc.},
title = {Discovery of the Hidden World with Large Language Models},
url = {https://proceedings.neurips.cc/paper_files/paper/2024/file/b99a07486702417d3b1bd64ec2cf74ad-Paper-Conference.pdf},
volume = {37},
year = {2024}
}